YOU DON'T NEED A STUDIO.
YOU NEED A DATA PARTNER.
Most teams start hunting for studios in Mumbai, Bangalore, or Delhi — then discover they also need casting, scripting, direction, linguists, QC, and SFT-ready delivery. We handle all of it, in one engagement, across 20+ Indian cities.
Built by the team whose speech data trains AI used by hundreds of millions worldwide.
One team. One invoice. Complete datasets.
YOU DON'T NEED A STUDIO.
YOU NEED A DATA PARTNER.
Most teams start by hunting for studios in Mumbai, Bangalore, or Delhi — then discover they also need casting, scripting, direction, linguists, QC, and SFT-ready delivery. We handle all of it, in one engagement, across 20+ Indian cities.
Built by the team whose speech data trains AI used by hundreds of millions worldwide.
One team. One invoice. Complete datasets.
WE DON'T FIND STUDIOS.
WE REBUILD THEM.
99% of studios in India would fail an AI dataset audit. So we don't book rooms — we scout, gut, rewire, and certify every space ourselves, to a spec measured in dBFS and RT60. Every studio in our network has been through all four steps.
Scout
Hand-picked rooms across Indian cities.
Rebuild
Acoustic panels, floating floors, sealed HVAC.
Rewire
Clean power, grounding, shielded signal.
Certify
Measured end-to-end. No badge until every target is hit.
Certified studios across India. Trusted by the biggest AI teams in the world.
The Proof
WE DON'T FIND STUDIOS.
WE REBUILD THEM.
99% of recording studios in India would fail an AI dataset audit — acoustically leaky, electrically noisy, built for podcasts and jingles, not token-level training data. So we don't book rooms. We scout, gut, rewire, and certify every space ourselves, to a spec measured in dBFS and RT60, not vibes. Every studio in our network has been through all four steps.
Scout
Hand-picked rooms across Indian cities — chosen for raw acoustic potential.
Rebuild
RT60 < 0.1sAcoustic panels, floating floors, sealed HVAC, isolation treatment.
Rewire
Zero EMIClean power, proper grounding, shielded signal chains.
Certify
< −60dBMeasured end-to-end. No badge until every target is hit.
Certified studios across India. Trusted by the biggest AI teams in the world.
The Proof
WE DON'T SCOUT VOICES.
WE CAST PERSONAS.
Booking a studio is the easy part. The voice inside the studio is what trains the model — and a wrong-cast talent contaminates an entire dataset. We run full casting cycles for every brief: 2,000+ talent across every major Indian city, 12 Indian languages, screened by voice directors and staff linguists before anyone hits record.
The voice inside the studio trains the model — and a wrong cast contaminates the entire dataset. 2,000+ talent, 12 languages, screened by voice directors and linguists before anyone hits record.
Casting Plan
12 languagesProfile the voice you need — language, dialect, age, gender, tone, emotional range.
Source
2,000+ voicesCurated network across Indian cities + open auditions when the brief demands it.
Multi-Phase Auditions
Directors + linguistsMultiple rounds of in-studio auditions screened by voice directors and linguists.
Talent Management
Schedules, contracts, retakes, on-set coordination — handled end-to-end.
Already cast 50+ talents across 10 languages for conversational AI personas at 5 of the world's biggest tech companies. Thousands of hours delivered.
The Casting Board
Warm & Natural
Conversational, approachable delivery
Authoritative
Confident, commanding presence
Youthful
Bright, energetic, under-30
Expressive
Rich range, dramatic depth
WE DESIGN HOW
PEOPLE ACTUALLY TALK.
A dataset is only as good as its prompts. Generic scripts produce generic models — stiff, unnatural, context-blind. Our linguists build content plans around how people actually speak in India: code-switched, disfluent, emotional, domain-specific. 12 script archetypes, engineered for the failure modes your model will hit in the real world.
Spontaneous Speech
Unscripted, naturally flowing talk
Solo Monologues
Single-speaker narratives & reads
Assistant ↔ User
Two-party AI interaction flows
Multi-Speaker
Group chats with turn-taking
Foundational Prompts
Phonetically-balanced coverage sets
Code-Switched Dialogue
Hinglish & cross-lingual mixing
Emotion-Specific
Happy, tense, sad, excited — on cue
Task-Oriented Commands
Intent-driven utterances & queries
Read Speech
Broadcast-clean scripted delivery
Domain-Specific
Healthcare, finance, retail, auto
Disfluency-Rich
Hesitations, restarts, fillers
Wake-Word & Triggers
Short activation & command clips
WE DON'T PRESS RECORD.
WE DIRECT EVERY TAKE.
WE DON'T PRESS RECORD.
WE DIRECT EVERY TAKE.
Every session runs in a Voqals-certified booth, supervised by a staff linguist, and directed for prosody, intent, and emotional target — not just clean reads. Dual-studio setups eliminate bleed on multi-speaker sessions. Zero client ops: talent scheduling, contracts, retakes, and take logs are all on us.
Certified Booth
RT60 < 0.1sNoise floor, RT60, and electrical interference measured before a mic goes live.
Directed Performance
Target prosodyEvery take coached for prosody, emotion, and target delivery — not just read.
Linguist-Supervised
Per sessionA staff linguist sits every session, verifying pronunciation, dialect, and script fidelity.
Handled End-to-End
Zero client opsTalent scheduling, contracts, retakes, take logs — all on us. You never chase a voice actor.
Every take ships to the Voqals quality standard. You never chase a voice actor. Nothing less.
Every Session Includes
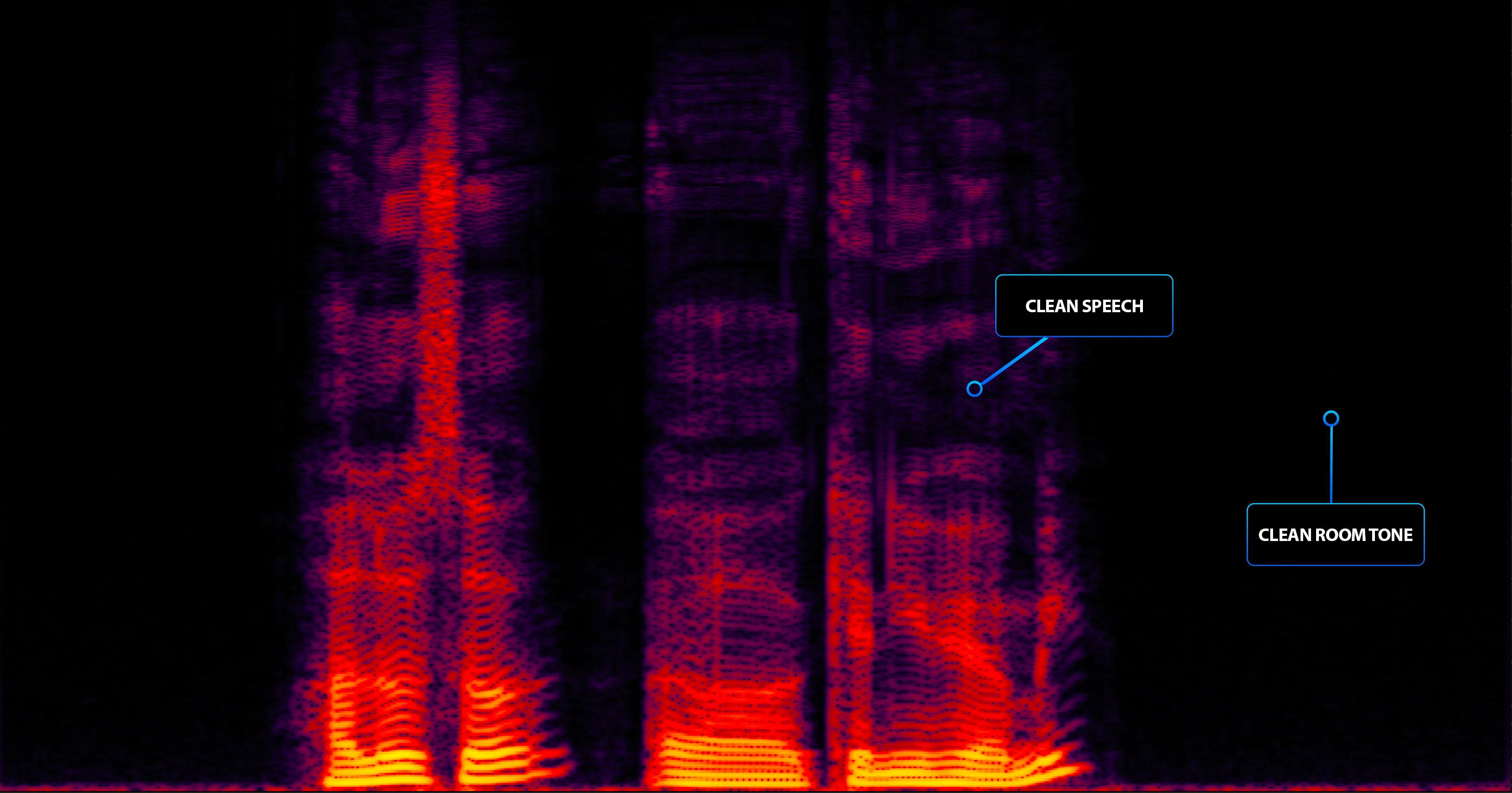
WE DON'T CLEAN RECORDINGS.
WE ENGINEER TOKENS.
WE DON'T CLEAN RECORDINGS.
WE ENGINEER TOKENS.
Even in a treated booth, artifacts happen. We slice every recording into utterance-level tokens first, clean each one down to the waveform, then master to a single loudness and EQ target. The result: your model hears one consistent voice across 10,000 utterances, not ten thousand mixes. Two QC rounds — one human, one software — before anything ships.
Utterance Tokenization
Zero-crossing cutsZero-crossing cuts — one phrase, one file.
Artifact Cleanup
Per tokenClicks, plosives, breath, sibilance — surgically removed.
Per-Token Mastering
TTS-gradeSame loudness, EQ, and peak ceiling across every token.
Dual QC
2 roundsHuman ear-check, then software verifies LUFS and peaks.
Token Pipeline
SEND US A BRIEF.
GET A FULL SCOPE IN 48 HOURS.
Already trusted by 5 of the world's biggest tech companies across 12 Indian languages and thousands of delivered hours. Send us what your model needs — languages, hours, use case, timeline — and within 48 hours you get a complete scope, talent samples, and a transparent quote. No discovery-call runaround. No vague estimates. One partner, end-to-end.
Custom Scope Doc
Languages, talent profiles, script structure, acoustic spec, and delivery format — written for your model.
Production Calendar
Studio bookings, casting calls, recording dates, and QC milestones — sequenced end-to-end.
Transparent Quote
Per-hour or per-token pricing. No surprise line items. Sign and recording starts the following week.
Backed by Voqals MediaTech Pvt. Ltd. — India's end-to-end speech data partner.
LET'S BUILD
YOUR DATASET.
Whether you need a bespoke collection built from scratch or instant access to our production datasets, our team is ready to scope your exact requirements. Tell us your use case, your languages, and your volume — we'll take it from there.
Datasets & custom data collection enquiries
Talents, studios & vendor enquiries
LET'S BUILD
YOUR DATASET.
Datasets & custom data collection
Talents, studios & vendors